Metadaten-Lookup für Fremdsysteme
Warning
Dieser Abschnitt ist für IT-Profis /Programmierer gedacht, nicht für normale Anwender geeignet!
Allgemein
Es kann notwendig sein, zu dem eigentlichen Dokument Zusatzinformationen aus anderen Systemen an ecoDMS mit zu übergeben. Dafür ist der Lookup gedacht.
Ein Lookup kann zum Beispiel in einem SQL Server, einer JSON-Datei oder einer Excel-Datei Daten nachschlagen und diese zusätzlich zu dem Dokument an ecoDMS übergeben.
Typische Anwendungsfälle sind:
- Ein Ordner enthält die Kundennummer, aber in ecoDMS soll der Namen des Kunden als Attribut geschieben werden. Dazu wird die Kundennummer aus dem Ordner in der Adress Tabelle des Fremdsystems nachgeschlagen und schlussendlich der Kundenname in ecoDMS gespeichert.
- Ein Programm exportiert zusätzlich zur PDF-Datei noch eine JSON-Datei mit Buchungsdaten die den Status des Dokumentes beschreiben, diese sollen mit in ecoDMS als Attribut importiert werden sollen.
Das lookup System ist expiziert Modular aufgebaut und kann leicht erweitert werden.
Aktuell werden folgende Lookup-Arten unterstützt:
- json: Importiert eine oder mehrere JSON-Dateien aus einem angegebenen Pfad.
- mssql: Importiert Daten aus einem Microsoft SQL Server via ODBC.
Aufbau
Prinzipiell funktioniert ein Lookup wie folgt:
-
In dem Mapping Attributen ist ein Lookup für ein Attribut definiert, z.B.
<@lookup(adressen.firstname)>. Dies weist Arkivado an, die Spaltefirstnameaus der Tabelleadressenzu verwenden.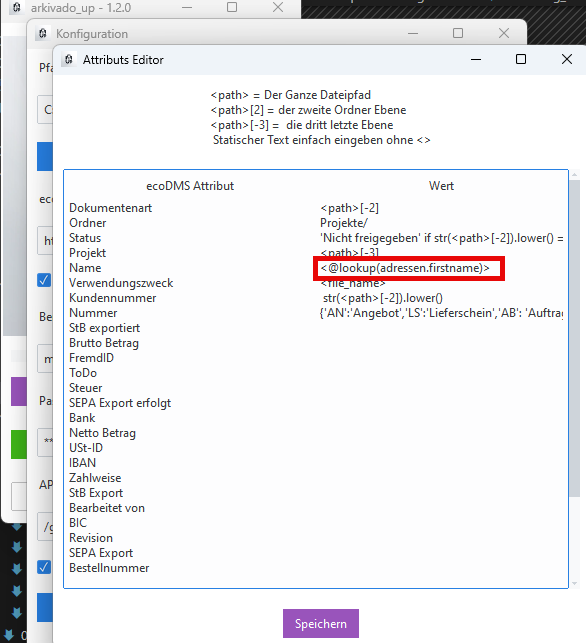
-
in der Konfigurationsdatei
params.jsonmehr infos hier wird im Unterpunktlookupdefiniert welche Systeme abgefragt werden. - Beim import Start werden dann alle lookup Quellen aktualisiert und stehen zum Nachschlagen bereit.
- Den Abschnitt
joinim Lookup gibt an, welcher Teil des Pfades / Dateinamen als Bindeglied genommen werden sollen. - Über Aliase können die Teile des Pfades oder Dateinamen definiert werden, die zum Joinen verwendet werden.
Falls Sie hilfe benötigen: Kontakt
hier eine "fertige" Konfigurationsdatei:
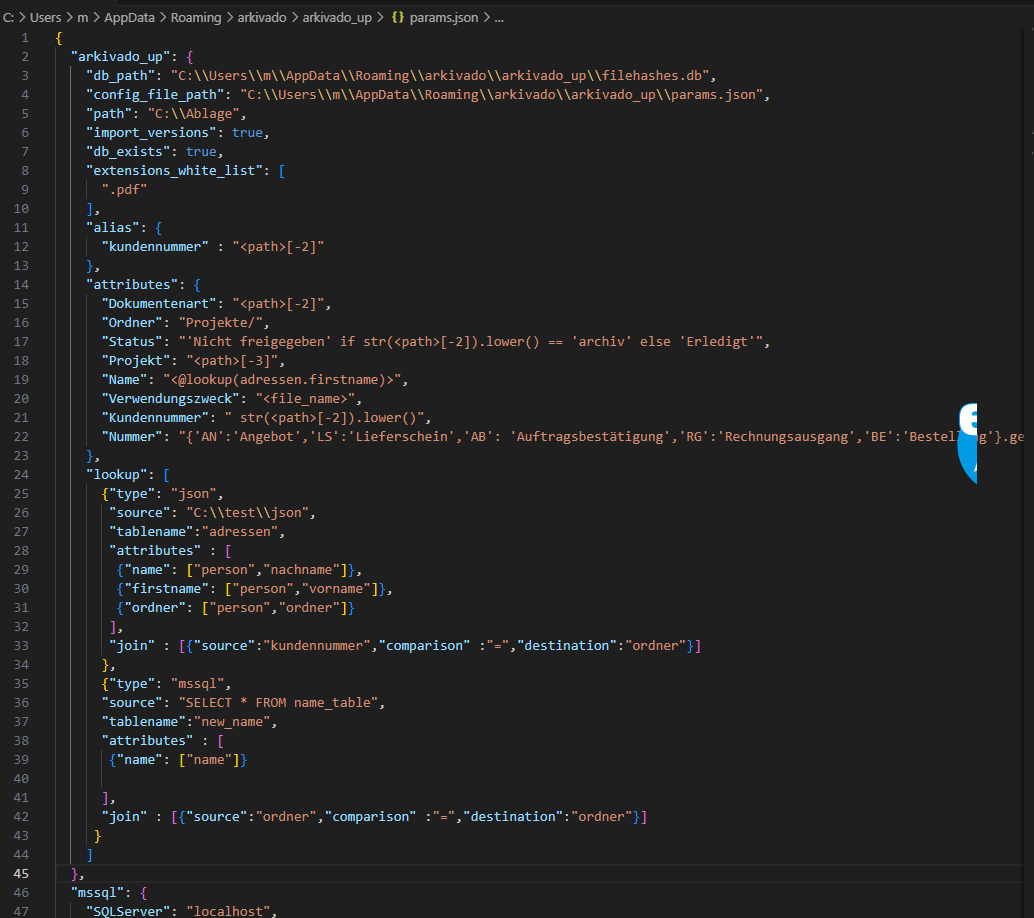
Die Einzelnen Einträge werden nun im Detail erklärt
Lookup
Die Konfigurationsdatei params.json muss um den Punkt lookup erweitert werden.
{
"lookup": [
{"type": "json",
"source": "C:\\test\\json",
"tablename":"adressen",
"attributes" : [
{"name": ["person","nachname"]},
{"firstname": ["person","vorname"]},
{"ordner": ["person","ordner"]}
],
"join" : [{"source":"kundennummer","comparison" :"=","destination":"ordner"}]
}
]
}
Es können beliebig viele Lookups konfiguriert werden.
Ein Lookup besteht immer aus folgenden Punkten:
| JSON Key | Bedeutung | Beispiel |
|---|---|---|
type |
Der Lookup-Typ, der durchgeführt werden soll, z.B. mssql oder json | json |
source |
Die Quelle der Daten. Bei JSON ist dies der Pfad, bei SQL die Abfrage | C:\\test\\json |
tablename |
Der interne Tabellenname in der Arkivado Up-Datenbank. Dieser muss eindeutig sein und wird mit dem Befehl @lookup referenziert | adressen |
attributes |
Gibt an, wie die Attribute in der Arkivado Up-Datenbank gespeichert werden. Das Attribut heißt in der Arkivado-Datenbank name und kommt aus dem Unterschlüssel person -> nachname in der JSON |
[{"name": ["person","nachname"]}] |
join |
Gibt an, wie die Daten zwischen der Datei und den Lookup-Daten verbunden werden sollen. Dabei ist source das Feld im Pfad bzw. Dateinamen und destination der Name in der Metadatentabelle |
Alias
Damit ein JOIN funktionieren kann, wird oftmals ein Teil des Pfades benötigt, um darauf zu joinen.
Beispielsweise lautet der gesamte Pfad zu einer Datei:
mit <path> kann auf den gesamten Pfad zugegriffen werden.
Die Kundennummer steckt im letzten Ordnername und lautet 1234.
Damit der Join funktioniert, muss definiert werden, dass nicht der gesamte Pfad genommen wird, sondern nur der Teil des Pfades. Die Sytax dafür entspricht der, des Mappings siehe hier.
In der JSON wird das Alias so angebeben:
Konktet heißt dass, im join und auch in den attributes der Teil des Pfades (letzter Ordnername) mit<kundennummer> verwendet werden kann.
Der Name des Alias wird am Anfang angegeben, gefolgt von der Abbildungsvorschrift, wie im Mapping.
Technischer Hinweis
Ein Alias wird in der Arkivado-Datenbank als zusätzliche Spalte angelegt und ermöglicht so einen JOIN.
JSON-spezifisch
- Die Angabe bei source kann entweder ein Ordner sein, in dem alle JSON-Dateien durchsucht werden, oder eine spezifische einzelne Datei.
- Bei den Attributen wird im zweiten Teil der "Pfad" zur Information angegeben.
Sieht die JSON-Datei beispielsweise so aus:
kann auf die Schlüssel mit folgender Syntax zugegriffen werden:
[
{"name": ["person","nachname"]},
{"firstname": ["person","vorname"]},
{"ordner": ["person","ordner"]}
]
MS SQL-spezifisch
Zusätzlich zur allgemeinen Konfiguration wird ein SQL-spezifischer Teil benötigt, um Servername, Datenbankname und Benutzername anzugeben.
Danger
Es wird DRINGEND empfohlen, mit einer Windows-Authentifizierung zu arbeiten! (SQLUseWindowsAuth = true)
"mssql": {
"SQLServer": "localhost",
"SQLDatabase": "test",
"SQLUsername": "domain\\benutzername",
"SQLpassword": "MeinTollesPasswort",
"SQLUseWindowsAuth": true,
"SQLPort": "1433"
},
| JSON Key | Bedeutung | Beispiel |
|---|---|---|
SQLServer |
Hostname oder IP des SQL Servers | localhost |
SQLDatabase |
Der Datenbankname innerhalb des SQL Servers | test |
SQLUsername |
Der Usernamen mit dem die Authentifizierung stattfindet, achtung: \\ JSON schreibweise beachten ! |
domain\\benutzername |
SQLpassword |
Das SQL Server Passwort, es wird empfohlen die Windows Authentifizierung zu verwenden: SQLUseWindowsAuth damit hier kein Passwort im Klartext steht! |
MeinTollesPasswort |
SQLUseWindowsAuth |
bei true wird die Windows Anmledung verwendet. Das Passwort wird dann ignoriert | true |
SQLPort |
Der Port unter dem der SQL Server erreichbar ist, standard: 1433 | 1433 |